“What’s New?” is a series of blog posts covering recent changes to Comet in more detail. This article covers the latest changes in Comet Voyager over April 2023.
There were five Comet software releases during April – four in the weekly 23.3.x Voyager release series, plus one minor patch update 23.2.2 for our quarterly “Leda” release track. We’ve also released a new YouTube tutorial for the new Object Lock feature!
There were some very large and exciting features released in Voyager during April:
New design for the Comet Server web interface
When upgrading to Comet Server 23.3.3, you’ll be greeted with a new experience:
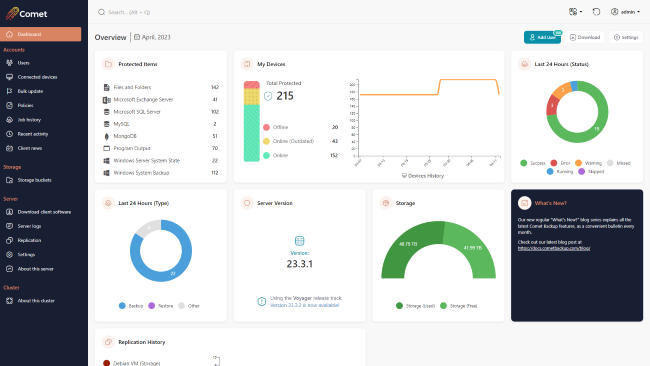
This is the first major Comet Server web interface upgrade in six years. We’re very excited and proud of the new layout. The left-aligned navigation bar allows for faster navigation to pages without clicking through menus, and the quick search bar has been modernized. The new design has also expanded the set of colour customization options that are available: in addition to setting your custom brand colour, you can also set an accent colour for highlights.
The homepage has seen the most dramatic change, including new navigation buttons on the top-right and a rework of all the admin widgets. There are new widgets showing how many of each Protected Item type is being used; how much used/free space there is on your Storage Role data location; the status and last run time of your Server Self-Backup; a live real-time chart of replication progress; and more.
The policies page has also been redesigned. As we add more and more policy options in new versions of Comet, we split the long Policy section to use sub-tabs. This includes a summary page, and a new feature to suggest possible common file path exclusions. We’re continuing to work on additional Policy features, and you can expect to see a highly-voted feature coming soon!
When looking at a user account, on the Protected Items tab, the new user interface design has also added a quick-access “Run Backup” button that can remotely command the device to start a backup job. Previously, this feature was available from the Connected Devices page or from the Devices tab – but adding it to the Protected Items tab is a significantly more convenient place, and demonstrates this functionality more clearly to new Comet administrators.
We would appreciate hearing your feedback on the new web interface design before it lands in the upcoming quarterly release!
Search restore from web
When restoring data, Comet prompts you for the Storage Vault to restore from; the backup snapshot to browse inside; and then the file (or all files), respectively. However if you’re trying to restore a single file without knowing exactly when it was last available, or what folder it was inside, Comet’s Search button can search through all backup job snapshots to find the right match.
The Search button has been available on the Restore dialog in the desktop app for a while. New in Comet 23.3.4 is the ability to remotely perform a file search for restore from the Comet Server web interface.

Test Connection for Storage Templates
Comet is highly flexible in the number of ways you can configure your storage. From the customer’s device running Comet Backup, a Storage Vault could point to a local path; directly at a cloud storage provider; or to your Comet Server with Storage Role enabled – which could then receive the data and store it on a local RAID array or forward it to another cloud storage provider.
Storage Templates are the provisioning system for new Storage Vaults. If you set up a Storage Template for Wasabi or Backblaze, you gain the ability to provision private, per-customer cloud buckets and access credentials with a single click. If you enable Storage Role for receiving data into your Comet Server (or another clustered Comet Server), using a Storage Template can help to very easily provision new Storage Role buckets for each customer.
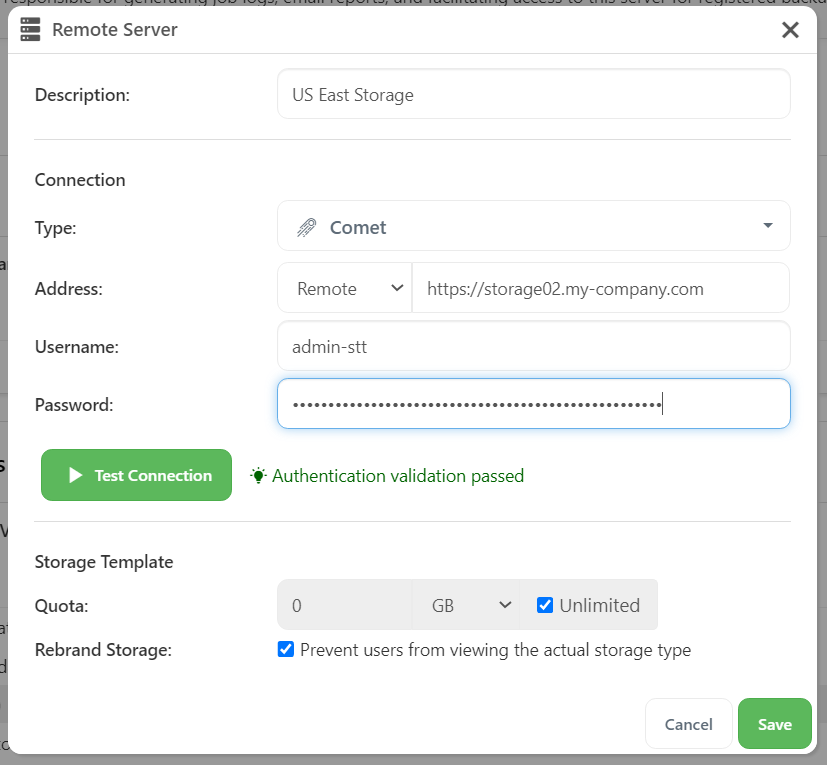
Comet has long supported a Test Connection button on the Storage Vault page, to check that your custom entered credentials are valid. But when setting up a Storage Template for the first time, the only way to verify that everything was functioning was to attempt to provision a new Storage Vault for a test customer.
In Comet 23.3.5, a new Test Connection button was added to the Storage Template configuration popup in the Comet Server web interface. This allows you to quickly verify that your template is working as expected.
Self-Backup
Comet Backup requires a connection to a Comet Server to safely store its configuration. But if you are self-hosting the Comet Server application, the Comet Server also should be backed up to mitigate against the risk of data loss. However, you can’t really use Comet Backup for this purpose, since this creates a circular dependency during recovery.
As a solution, Comet Server includes the Server Self-Backup feature. This creates a consistent snapshot of Comet’s configuration files, and allows you to store it encrypted on any supported storage location, including cloud storage. Multiple targets, custom scheduling, and data retention policies are all supported. The files are simple zip files to ensure that any eventual necessary restore is an easy and low-stress process.
The latest version of Comet Server made improvements to the Server Self-Backup feature. The generated filenames now clearly show the date and time of the backup job, instead of solely an epoch timestamp. Any automatic SSL certificate files provisioned by Let’s Encrypt are now included in the archive, ensuring that it is not required to reissue the certificate. This helps avoid any issues with rate limits on the Let’s Encrypt service, which could otherwise prolong your service outage.
We’ve also added a new option to include server log files in the Self-Backup archive. These log files are not generally required, but for completeness or for an investigation, they can provide an additional view into the circumstances behind the event.
Codesigned uninstallers
Microsoft, along with third-party security vendors, continue to harden the security posture of the Windows operating system. Comet Backup’s client installer is codesigned – either by our company, or if you are using custom branding, then possibly with your own custom codesigning certificate. However over time, the security hardening has increased, and we’ve recently heard reports that the uninstaller for Comet Backup could trigger alerts in some security products. As a result, the latest versions of Comet Server apply Authenticode codesigning to the uninstaller to help avoid this issue.
The 23.5 Quarterly release is coming soon
At Comet, we release our software under two tracks – the “Voyager” release track approximately weekly, with all of our very latest changes; and the quarterly release track, where we bundle up three months’ worth of development into a new fixed point for you to qualify, offer, and build upon, in order to provide a consistent experience for your own customers. Depending on your market position or your requirements, you may find either one of these tracks better suits your needs. As per our regular release schedule, you can expect a 23.5.0 quarterly release towards the end of this month, which will bring all of the exciting features to the quarterly track and also for Comet-Hosted users.
That’s all for this month! Thanks for reading – there are some more great features currently under development that we’re excited to be able to share with you soon. As always, please follow @CometBackup on Twitter and you can always contact us if you have any questions.